Greed Isn't a Good Policy
• 2 min read 2 min
What I worked on
Went back to the CMA ES paper with fresh eyes after actually using the algorithm. Understanding the maths helped clarified that nothing is wrong with CMA ES itself. It optimizes exactly what the fitness function gives it — survival time. This means it’s time to dig into policy design and how actions were chosen.
What I noticed
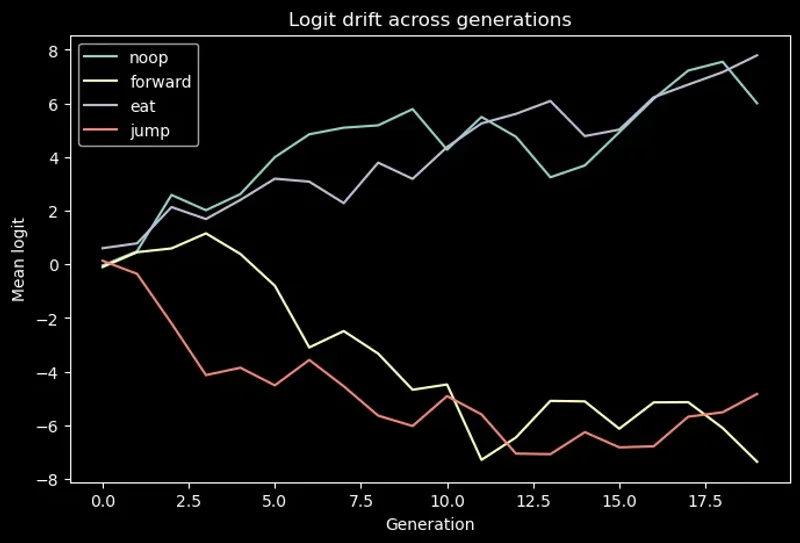
- Initial policy chose actions via . This was a simple/basic policy to start with that is greedy and always took the largest logit from the MLP. Model got stuck in a local optimum so learnt that that staying still was always safer than moving. Expected reward for NOOP looked good locally but was capped globally.
- Using argmax produced long runs of repeated action (i.e. EAT, EAT, EAT, …) because the policy had no mechanism to sample anything else besides largest logit.
- Switching to a softmax with temperature let the policy sample from a probability distribution instead of always taking the max. This created variation in the action sequences and opened up more of the action space to explore.
”Aha” Moment
- n/a
What still feels messy
- Temperature at training time feels like it would become problematic at validation
- Stochastic policy is better now but feels like it’s still capped globally.
Next step
- Continue to improve the policy
- Need to move way from the idea of train/test and towards something more continuous