Paper Club - Intrinsic Motivation For RL
• 2 min read 2 min
What I worked on
Read a few papers on curiosity and intrinsic motivation.
| Title | Authors | Year | Link |
|---|---|---|---|
| Intrinsic Motivation For Reinforcement Learning Systems | Barto, Andrew G. | n.d. | — |
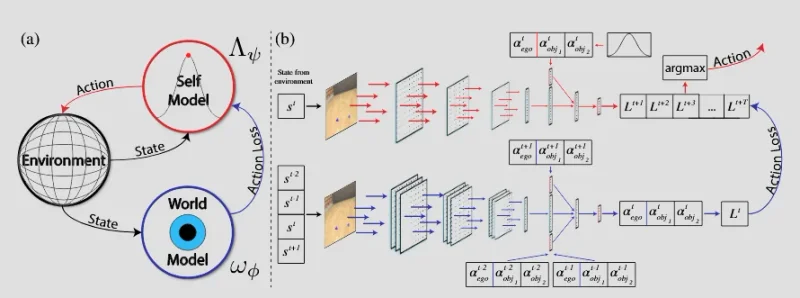
| Learning to Play with Intrinsically-Motivated Self-Aware Agents | Haber, Nick; Mrowca, Damian; Fei-Fei, Li; Yamins, Daniel LK | 2018 | https://doi.org/10.48550/arXiv.1802.07442 |
| Computational Theories of Curiosity-Driven Learning | Oudeyer, Pierre-Yves | 2018 | https://doi.org/10.48550/arXiv.1802.10546 |
| Intrinsic Motivation Systems for Autonomous Mental Development | Oudeyer, Pierre-Yves; Kaplan, Frédéric; Hafner, Verena V. | 2007 | https://doi.org/10.1109/TEVC.2006.890271 |
| How Can We Define Intrinsic Motivation? | Oudeyer, Pierre-Yves; Kaplan, Frédéric | n.d. | — |
| Curiosity-Driven Exploration by Self-Supervised Prediction | Pathak, Deepak; Agrawal, Pulkit; Efros, Alexei A.; Darrell, Trevor | 2017 | https://doi.org/10.48550/arXiv.1705.05363 |
| Don’t Do What Doesn’t Matter: Intrinsic Motivation with Action Usefulness | Seurin, Mathieu; Strub, Florian; Preux, Philippe; Pietquin, Olivier | 2021 | https://doi.org/10.48550/arXiv.2105.09992 |
What I noticed
- I like the idea of the agent learning about the environment dynamics vs comparing ∞ states. Actions are finite so it scales.
- Curiosity-based exploration has been historically about a forward model that tries to predict the next state/features. A high prediction error is used as the intrinsic reward because it means something surprising happened.
- Memory didn’t come up much but I like it.
- Store vectors (this allows for easy similarity comparisons)
- Count actions
- Learnt about an “inverse model” to predict the action that caused the transition.
- Curiosity is “an efficient way to bootstrap learning when there is no information” - Oudeyer
- World models seem to be the backbone for predicting action consequences. Love how this ties back into my earlier work.
”Aha” Moment
- n/a
What still feels messy
- Barto says all reward is intrinsic if you move the critic from the external environment into the agent’s internal environment. I’m not sure I believe that in the general case but it’s true enough for my scenario.
- Is curiosity expressing positive or negative valence? Need to think about this more.
Next step
- Come up with a new policy based on these ideas
- If I can add JEPA as a way to represent state that would be interesting. BUT JEPA requires SGD and I’m using ES, and I want dynamics not representation.