Reward Shaping Bitter Lesson
• 2 min read 2 min
What I worked on
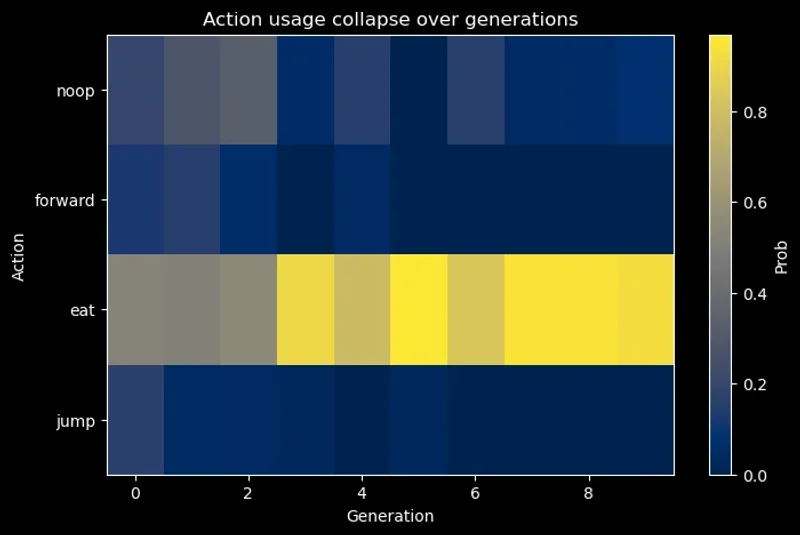
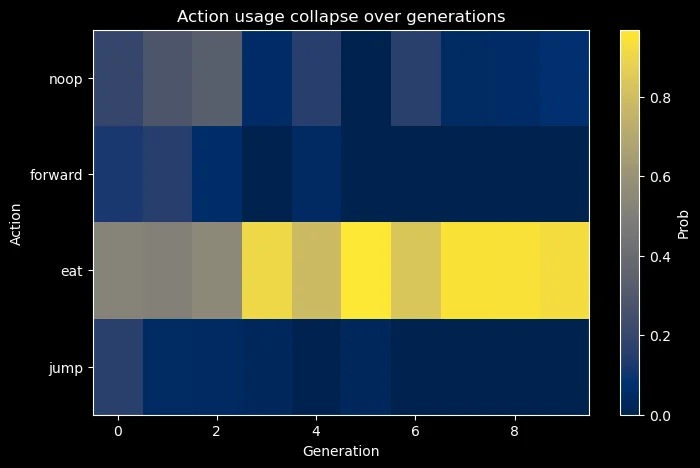
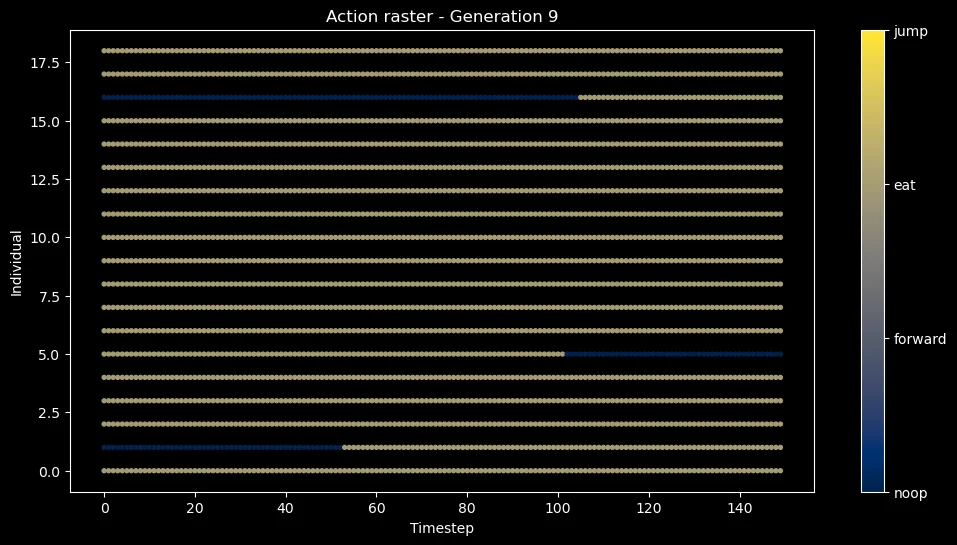
Added an additional JUMP action and immediately saw a collapse in the search space for the non-linear policy.
What I noticed
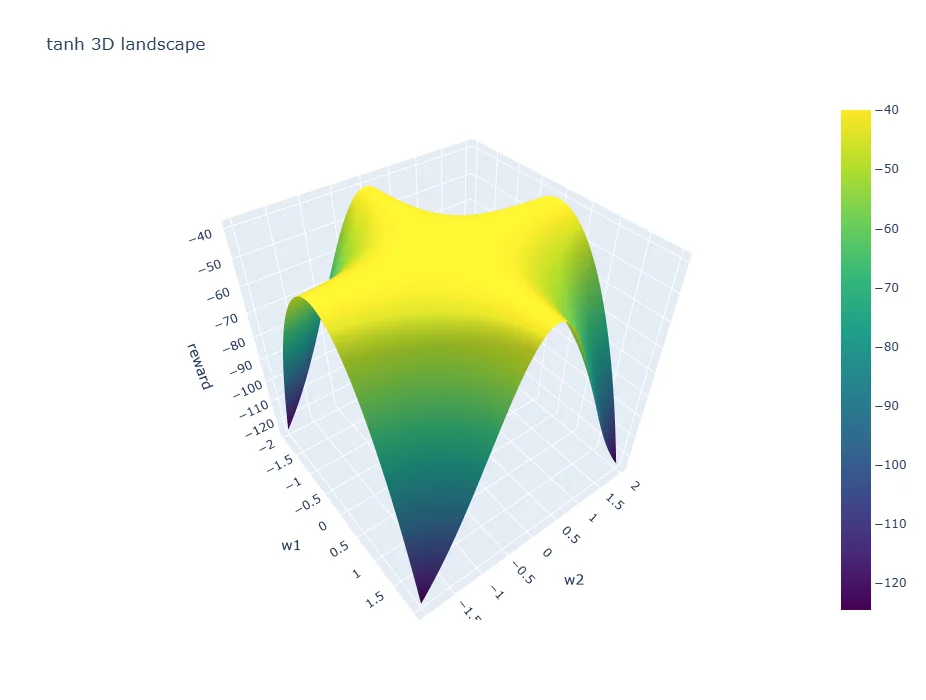
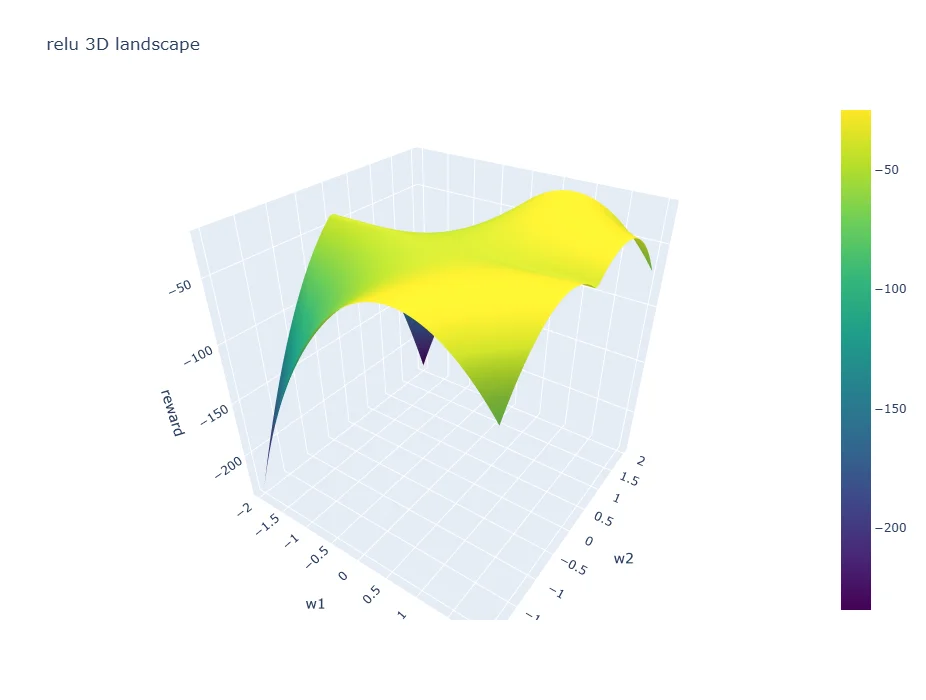
- Changing the activation function from ReLU to tanh smoothed the search space but didn’t help avoid shrinking parameter space
-
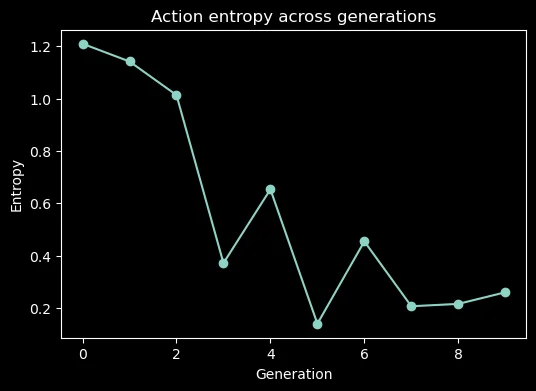
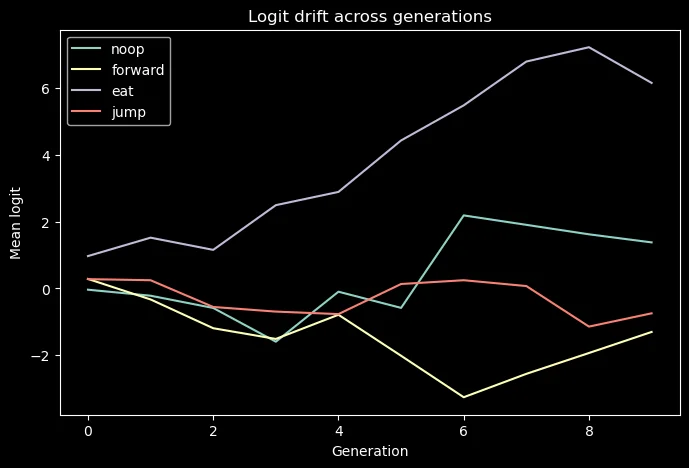
Actions that maximized reward early on (NOOP, EAT) resulted in CMA-ES sampling a distribution that’s shrunk.
-
Changing ENV dynamics (NOOP >= FORWARD) encouraged exploration
-
Almost identical states lead to different policies so is anything being learnt?
-
Trimmed down features from 11 to 5 didn’t have any impact
”Aha” Moment
- I now understand why policies need entropy/action diversity into the objective
- This type of engineering (i.e. reward shaping, encouraging entropy, hand-engineered features) is the bitter lesson
What still feels messy
- CMA-ES is optimizing over long haul, so scenarios where there is exploration that result in low scores are viewed negatively
- I want to avoid the bitter lesson but that doesn’t seem possible this early on
- Extremely frustrating that it’s hard to understand the policy once you introduce the hidden layer(s)
Next step
- I’m purposely going to stay away from more generations, bigger population, larger standard deviation, reward hacking, encouraging entropy
- Think/play around about what a good action means. I don’t want to encourage entropy but I want to be able to determine positive and negative “valence”