Evolutionary Prompt Optimization & Bootstrapped Coding Agents
What I worked on
My hypothesis is that today’s LLMs could match a great developer if they understood the customer, value props, and business context.
What you can do with agentic systems today is amazing, but it’s not good enough yet. Still, taken to its limit, AI is clearly going to change software development. The question is how to use today’s agentic systems to approximate that future state. I keep coming back to moving the agent closer to the customer.
Current LLMs are as capable as an average developer. The gap between average and great developers is judgement. I always taught my PMs to “squeeze out the ambiguity” because ambiguity causes churn and that costs momentum. The PM is the voice of the customer, but even simple requirements like loading files can hide so much complexity. An average developer asks about lazy loading, caching, and constraints. This forces the PM to go back and think through the scenarios. A great developer understands the customer and the business so they are able to make those decisions automatically. Our job is to give the agent that same context so it can make the right decision.
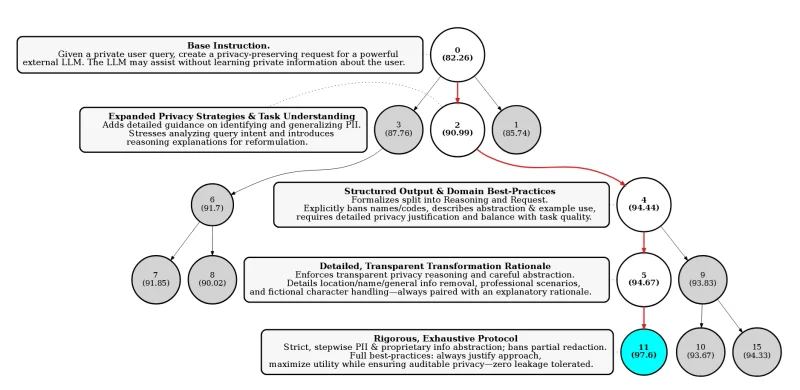
My first attempt to test this uses GEPA, an evolutionary algorithm in a simpler form. The experiment is to build a bootstrapped agentic coding system that improves itself. Initially everything is built using an existing agentic loop like Codex or Antigrav or OpenCoder. Once the agent can execute its own code, it will use GEPA to refine its coding policy. The real test is whether the agent can learn how I code. Can it take over from me based on how I deterministically score its output?
What I noticed
GEPA does not care about the code itself. It allows the agent to learn a prompting policy rather than relying on static prompts.
”Aha” Moment
Most open source agentic CLIs allow you to customize agent loops, but no attention is paid to improving the output of those agents over time. The responsibility of code quality is pushed onto the user or the LLM itself.
What still feels messy
- How to design a deterministic eval system
- How do these prompt policies evolve over time
- What’s the optimization budget
Next step
Keep building