GEPA in the Loop
• 1 min read 1 min
What I worked on
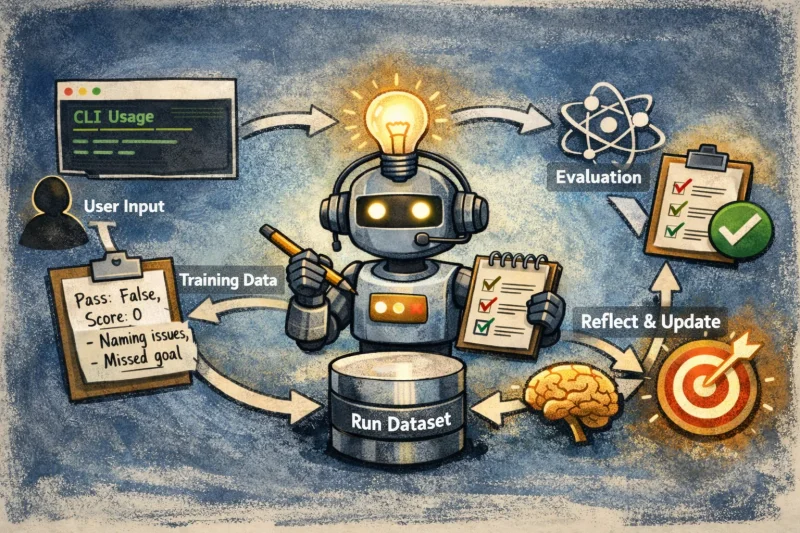
Designed and agentically implemented the full GEPA training loop rather than treating prompt optimization as an offline or synthetic task. It looks like this:
flowchart TD
U[User] -->|types request| CLI[CLI]
CLI -->|goal + context| S[Server]
S --> AO[AgentOrchestrator]
AO --> BR[BundleResolver]
BR --> B[(Active Prompt Bundle)]
B --> LOOP[Agentic Loop Execution]
LOOP -->|artifacts| RUNS[(Run Store)]
LOOP -->|repeat across steps| LOOP
CLI -->|many requests over time| AO
RUNS --> DS[(Training Dataset)]
DS --> GEPA[GEPA Prompt Optimizer]
GEPA -->|spawn candidate bundle| CAND[Candidate Bundle]
CAND --> LOOP
LOOP --> EVAL[Evaluation Framework]
EVAL -->|score + flags| SCORES[(Scores Store)]
SCORES --> GEPA
GEPA -->|update active bundle| B
subgraph Eval Maturity
M1[Now: Manual validation]
M2[Next: Deterministic tests]
M3[Later: LLM judge]
M1 --> M2 --> M3
end
EVAL -. uses .-> M1
EVAL -. evolves to .-> M2
EVAL -. evolves to .-> M3
B -->|better prompts next time| AOWhat I noticed
- Strong law of small numbers but still increasing confidence that judgment is a friction point
- Despite having tests, the only way to verify the system worked was to manually run the CLI and inspect artifacts
- When I ask it to do something I’m unsure about myself (e.g. GEPA integration) the feedback I provide becomes much larger
”Aha” Moment
N/A
What still feels messy
- GEPA technically runs but doesn’t make useful predictions yet
- Current implementation isn’t doing reflective mutation via an LLM
- I’m passing one practice/policy but real behavior comes from multiple practices/policies acting together
Next step
- Revisit GEPA setup to support reflective mutation & validate full run