JEPA Valence Standalone Experiment
• 1 min read 1 min
What I worked on
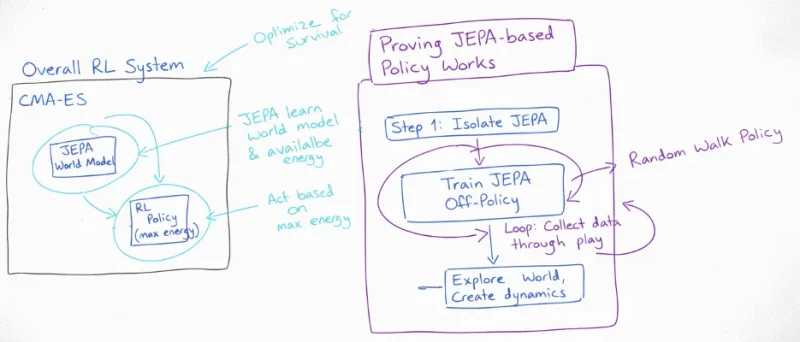
Thought about the critical path for using JEPA as a valence-based policy to guide action selection. If JEPA can’t represent the world model and doesn’t learn that energy exists then the policy can’t work.
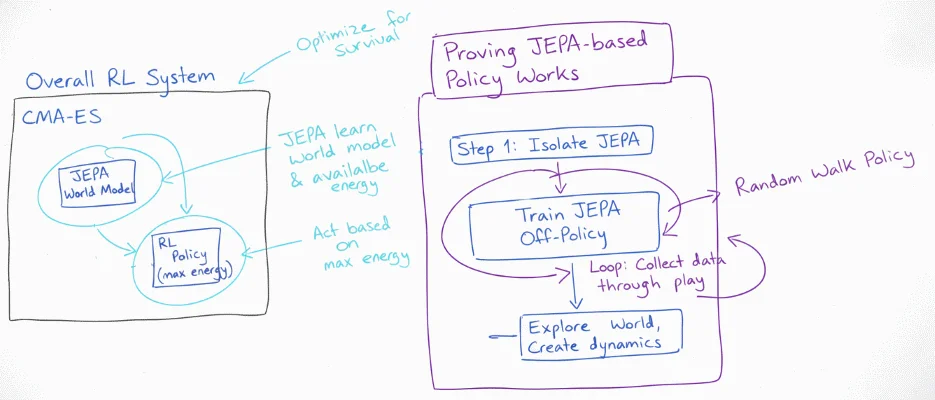
I created a standalone JEPA trainer that uses a dataset built from a random walk policy. The hope is that this simple dataset covers enough transitions for JEPA to learn a useful representation of the environment and most importantly that energy exists.
What I noticed
- My current probe is based on energy. I think that’s wrong. It should use
near_foodandcan_eatfeatures to learn energy is a consequence of exploring new states.
”Aha” Moment
n/a
What still feels messy
- No guarantee that random walk gives the right combination of actions to survive long enough for a good representation
- JEPA is being trained off-policy which pulls me further from my goal of continuous learning
Next step
- Run the training and see if the learnt representation captures the environment well enough