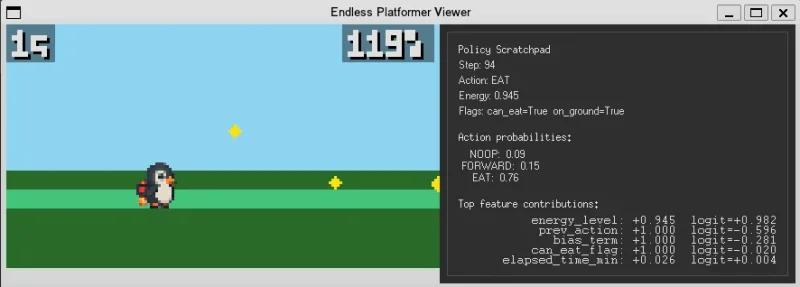
A Learned CMA-ES Policy to Survive
• 1 min read 1 min
What I worked on
- Read through the CMA-ES code to understand how policies, parameters, and features interact. Examined the act() function, evaluation logic, population size calculations, and random seeding.
- Created my own “best policy”
What I noticed
act()maps observations to actions using features- Policies flatten parameters into vectors (θ)
- Horizon defines episode length
- Random seed variations affect population initialization
”Aha” Moment
- The output of this policy was a linear policy that selected an action
- This is the equivalent to a single layer perceptron except in how it learns - no back prop
- SLP learns from supervised training, CMA-SE learns from fitness signal
- SLP learns the gradient but CMA-SE estimates over promising preturbing
- SLP is local but CMA-SE is global needing the whole episode
What still feels messy
CMA-ES is searching the parameter space and learning what matters but needs the full episode. For a multi-layered network it’s shifting all weights. That doesn’t sound efficient.
Next step
Create a multi-layered network and introduce JUMP to see how it learns the best policy.