Text Similarity Approaches
• 1 min read 1 min
What I worked on
Explored ways to measure text similarity and handle transcription confidence in ASR systems. Looked at multiple-model comparison and top-k predictions.
What I noticed
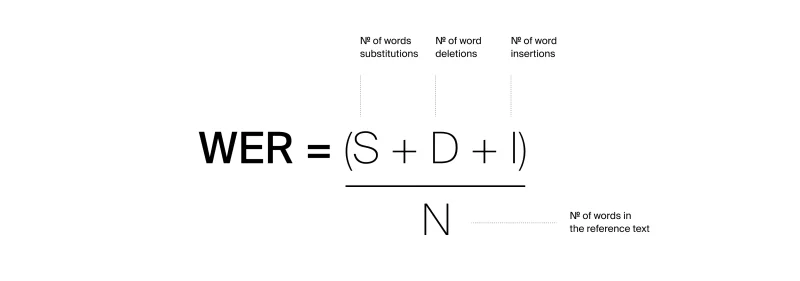
- WER or statistical comparison can check output consistency
- A decoder can return top-k alternatives with probabilities
- Low-confidence predictions could output “unknown”
- Phoneme errors like “low fever” vs “no fever” matter clinically
”Aha” Moment
n/a
What still feels messy
Still unclear which metric (WER vs probability threshold) provides the most reliable safety signal.
Next step
Prototype a simple top-k decoder and compare its confidence handling to multi-model WER.