Representation Learning in wav2vec Models
• 1 min read 1 min
What I worked on
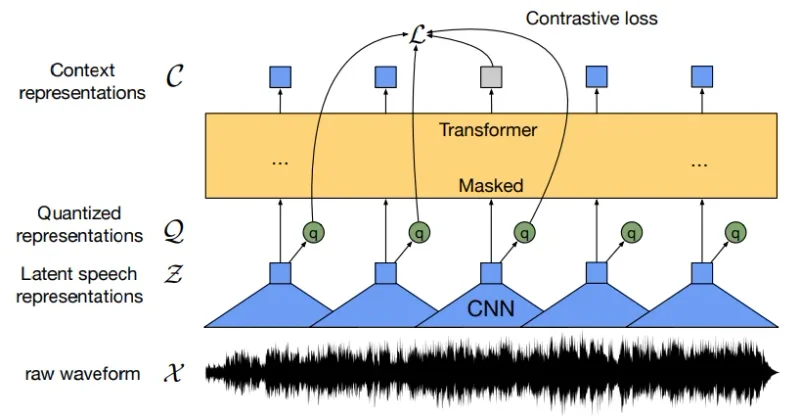
Explored how wav2vec 2.0 and vq‑wav2vec learn from raw audio and differ in how they represent speech features.
What I noticed
- wav2vec 2.0 masks latent representations and learns through contrastive prediction.
- vq‑wav2vec discretizes features into quantized codes and reconstructs them to predict context.
- wav2vec 2.0 is end‑to‑end and continuous, while vq‑wav2vec is discrete and symbolic.
- Visualization and probing methods (e.g., t‑SNE, PCA) can help interpret feature embeddings.
”Aha” Moment
wav2vec 2.0 and vq‑wav2vec represent two ends of the representation‑learning spectrum. Continuous contextual embeddings versus discrete symbolic codes that are both driven by self‑supervised objectives.
What still feels messy
How exactly discrete versus continuous embeddings affect downstream generalization and interpretability.
Next step
Run visualization or probing experiments on wav2vec 2.0 embeddings to examine structure or clustering.