Encoder Neural Network Explanation
• 1 min read 1 min
What I worked on
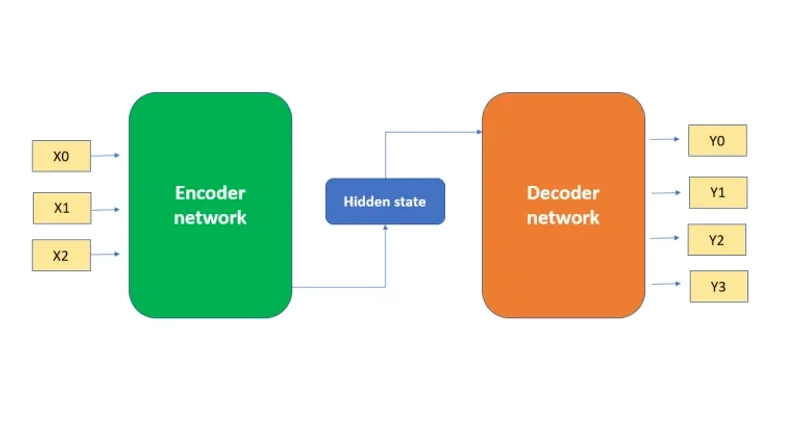
Clarified how encoders compress input features into lower-dimensional representations and how this connects to JEPA architectures.
What I noticed
- Encoders reduce dimensionality through learned compression
- JEPA uses a multi-block masking approach for context and target blocks
”Aha” Moment
Encoders aren’t just compression layers. They create representations that preserve structure useful for prediction.
What still feels messy
Still figuring out best practices for block-based masking in JEPA.
Next step
Prototype a simple encoder-decoder pipeline using multi-block masking.